Cap. 20 - Diccionarios
Todos los tipos de datos compuestos que hemos estudiado con detalle hasta ahora - strings, listas y tuplas - son tipos secuenciales, que usan enteros como índices para acceder a los valores que contienen.
Los Diccionarios son otro tipo de datos compuesto. Son el tipo de mapeo built-in de Python. Mapean claves, que pueden ser de cualquier tipo inmutable, a valores, que pueden ser de cualquier tipo (heterogéneos), exactamente como los elementos de una tupla. En otros lenguajes se los llama arrays asociativos porque asocian una clave con un valor.
Como ejemplo, crearemos un diccionario para traducir palabras del inglés al español. Para este diccionario, las claves son strings.
Una forma de crear un diccionario es comenzar con el diccionario vacío y agregar pares clave:valor. El diccionario vacío se denota así: { }
>>> eng2sp = {}
>>> eng2sp["one"] = "uno"
>>> eng2sp["two"] = "dos"La primera asignación crea un diccionario de nombre eng2sp. Las siguientes asignaciones agregan nuevos pares clave:valor al diccionario. Podemos imprimir el valor actual del diccionario del modo habitual:
>>> print(eng2sp)
{"two": "dos", "one": "uno"}Los pares clave:valor del diccionario están separados por comas. Cada par contiene una clave y un valor separados por dos puntos.
Hashing
El orden de los pares puede no ser lo que esperamos. Python utiliza algoritmos complejos, diseñados para acceso rápido, para determinar si un par clave:valor está o no guardado en el diccionario.
- Para nuestros propósitos podemos pensar en dicho ordenamiento como impredecible.
Te estarás preguntando por qué existe el concepto de diccionario si el mismo concepto de mapear una clave a un valor ya se podría implementar mediante listas de tuplas:
>>> {"manzanas": 430, "bananas": 312, "naranjas": 525, "peras": 217}
{'peras': 217, 'manzanas': 430, 'naranjas': 525, 'bananas': 312}
>>> [('manzanas', 430), ('bananas', 312), ('naranjas', 525), ('peras', 217)]
[('manzanas', 430), ('bananas', 312), ('naranjas', 525), ('peras', 217)]La razón es que lo diccionarios son muy rápidos, implementados mediante una técnica conocida como hashing, que nos permite acceder a un valor muy rápido.
- Por el contrario, la implementación mediante una lista de tuplas es muy lenta.
- Para encontrar un valor asociado a una clave, deberíamos iterar a través de cada tupla, chequeando el elemento de índice 0.
- ¿Qué pasaría si la clave ni siquiera está en la lista? Deberíamos llegar hasta el final para poder asegurarlo.
Otra forma de crear diccionarios es proveer una lista de pares clave:valor utilizando la misma sintaxis que en el output previo:
>>> eng2sp = {"one": "uno", "two": "dos", "three": "tres"}No importa en qué orden escribimos los pares. Los valores en un diccionario se acceden con claves, no con índices, por lo cual no tenemos que preocuparnos por el orden.
Aquí vemos cómo se utiliza una clave para buscar el valor correspondiente:
>>> print(eng2sp["two"]) 'dos'
La clave "two" nos entrega el valor "dos".
Listas, tuplas y strings son casos de secuencias, porque en ellas los elementos están en orden. El diccionario es el primer tipo compuesto de datos que vemos que no es una secuencia, por lo cual no podemos indexar ni trocear (slice) un diccionario.
20.1) Operaciones de diccionarios
La sentencia del elimina un par clave:valor de un diccionario. Por ejemplo, el siguiente diccionario contiene los nombres de varios frutos y la cantidad de stock disponible de cada fruto:
>>> inventario = {"manzanas": 430, "bananas": 312, "naranjas": 525, "peras": 217}
>>> print(inventario)
{'peras': 217, 'manzanas': 430, 'naranjas': 525, 'bananas': 312}Si alguien compra todas las peras, podemos eliminar la entrada del diccionario:
>>> del inventario["peras"]
>>> print(inventario)
{'manzanas': 430, 'naranjas': 525, 'bananas': 312}O si esperamos que hayan más peras en el futuro, podemos simplemente mantener la clave peras con un valor asociado de 0:
>>> inventario["peras"] = 0
>>> print(inventario)
{'peras': 0, 'manzanas': 430, 'naranjas': 525, 'bananas': 312}La llegada de más bananas para incrementar el stock podría manejarse así:
>>> inventario["bananas"] += 200
>>> print(inventario)
{'peras': 0, 'manzanas': 430, 'naranjas': 525, 'bananas': 512}La función len también funciona en diccionarios. Devuelve la cantidad de pares clave:valor:
>>> len(inventario) 4
20.2) Métodos de diccionarios
Los diccionarios tienen unos cuantos métodos built-in muy útiles.
El método keys retorna lo que Python 3 llama una vista de sus claves subyacentes. Un objeto vista (view) tiene cierta similitud con el objeto range que ya hemos estado usando - es una promesa perezosa (lazy promise) de producir los elementos cuando sean necesarios durante el resto del programa. Podemos iterar a través de la vista, o convertirla en una lista haciendo así:
for k in eng2sp.keys(): # El orden de las claves k no está definido
print("Tengo la clave", k, "que mapea al valor", eng2sp[k])
ks = list(eng2sp.keys())
print(ks)Esto produce este output:
Tengo la clave three que mapea al valor tres Tengo la clave two que mapea al valor dos Tengo la clave one que mapea al valor uno ['three', 'two', 'one']
Es tan común iterar a través de las claves de un diccionario que podemos omitir el llamado a keys en el loop for - la iteración sobre un diccionario implícitamente itera sobre sus claves:
for k in eng2sp:
print("Tengo la clave", k)El método values es similar; retorna un objeto vista que puede convertirse en una lista:
>>> list(eng2sp.values()) ['tres', 'dos', 'uno']
- Observación: en caso de haber valores repetidos, por ejemplo si tenemos {'bananas': 20, 'naranjas': 20, 'pomelos': 30}, values retornará [20, 20, 30], es decir todas las apariciones de cada valor.
El método items también retorna una vista, que promete una lista de tuplas - una tupla para cada par clave:valor:
>>> list(eng2sp.items())
[('three', 'tres'), ('two', 'dos'), ('one', 'uno')]Las tuplas suelen ser útiles para obtener tanto la clave como el valor al mismo tiempo mientras estamos en un loop:
for (k,v) in eng2sp.items():
print("Tengo", k, "que mapea a", v)Esto produce:
Tengo three que mapea a tres Tengo two que mapea a dos Tengo one que mapea a uno
Los operadores in y not in pueden testear si una clave está en un diccionario:
>>> "one" in eng2sp True >>> "six" in eng2sp False >>> "tres" in eng2sp # Como se ve 'in' chequea la presencia de claves, no de valores False
Este método puede ser muy útil, ya que un intento de ver el valor de una clave no existente en un diccionario causa un error de tiempo de ejecución:
>>> eng2sp["dog"] Traceback (most recent call last): ... KeyError: 'dog'
20.3) Alias y copias de diccionarios
Como en el caso de las listas, como los diccionarios son mutables, necesitamos tener en cuenta si creamos un alias o una copia. Cada vez que dos variables se refieren a un mismo objeto, cambios en una afectarán a la otra.
Si queremos modificar un diccionario y mantener una copia del original, conviene usar el método copy. Por ejemplo, opuestos es un diccionario que contiene pares de opuestos:
>>> opuestos = {"arriba": "abajo", "correcto": "incorrecto", "sí": "no"}
>>> alias = opuestos
>>> copia = opuestos.copy() # Copia superficialEn este ejemplo, alias y opuestos se refieren al mismo objeto. En cambio copia se refiere a una copia nueva del mismo diccionario. Si modificamos alias, entonces opuestos también cambia:
>>> alias["correcto"] = "desprolijo" >>> opuestos["correcto"] 'desprolijo'
Si en cambio modificamos a copia, entonces opuestos no cambia:
>>> copia["correcto"] = "erróneo" >>> opuestos["correcto"] 'desprolijo'
20.4) Matrices dispersas
Ya hemos usado una lista de listas para representar matrices. Es una buena idea para una matriz cuyos valores son variables, pero consideremos una matriz dispersa como esta:

- Sobre el concepto matemático de matriz dispersa, se puede consultar el artículo Wikipedia: Matriz dispersa
La representación de lista contiene un montón de ceros:
matriz = [[0, 0, 0, 1, 0],
[0, 0, 0, 0, 0],
[0, 2, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 3, 0]]Una alternativa es usar un diccionario. Para las claves, podemos usar tuplas que contengan el número de fila y columna. Aquí está la presentación de la misma matriz como un diccionario:
>>> matriz = {(0, 3): 1, (2, 1): 2, (4, 3): 3}Sólo necesitamos tres pares clave:valor, una para cada elemento no nulo de la matriz. Cada clave es una tupla, y cada valor un entero.
Para acceder a un elemento de la matriz, podríamos usar el operador []:
>>> matriz[(0, 3)] 1
Observar que la sintaxis para la representación como diccionario no es la misma que la sintaxis para la representación como lista anidada. En vez de dos índices enteros, tenemos un único índice que es una tupla de enteros.
Tenemos un problema. Si especificamos uno de los elementos que valen cero, tendremos un error, porque no hay entradas en el diccionario para dichos elementos:
>>> matriz[(1, 3)] KeyError: (1, 3)
El método get resuelve el problema:
>>> matriz.get((0, 3), 0) 1
El primer argumento es la clave, el segundo argumento se el valor que get debería devolver si la clave no está en el diccionario.
>>> matriz.get((1, 3), 0) 0
- Observación: Esta convención sigue teniendo un problema, y es que no distingue el caso "0" del caso en que la clave está fuera de rango.
- (corresponde a una fila y columna de la matriz que realmente no existen)
Como vemos, get definitivamente mejora la semántica de las matrices dispersas. Una pena la sintaxis.
20.5) Creación y utilización de memos
Si estuviste probando la función fib del capítulo de recursión (la versión recursiva de la función para calcular los números de Fibonacci), habrás notado que cuanto más grande es el argumento, más tiempo tarda la función en retornar. Aun más, el tiempo de ejecución crece muy rápidamente.
- En una de nuestras máquinas, fib(20) termina casi instantáneamente, fib(30) tarda poco más de un segundo y fib(40) parece que nunca fuera a terminar.
Para comprender el por qué, considera este grafo de llamadas para fib con n = 4:
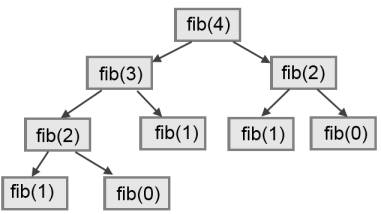
Un grafo de llamadas muestra cuadros con llamadas a funciones, con líneas conectando cada cuadro conectando a cada cuadro con los cuadros de las funciones que él llama. En el tope del grafo, fib con n = 4 llama a fib con n = 3 y a fib con n = 2. A su vez, fib con n = 3 llama a fib con n = 2 y fib con n = 1. Y así sucesivamente.
Cuenta cuántas veces son llamados fib(1) y fib(0). Se trata de una solución ineficiente del problema, y empeora rápidamente a medida que crece el argumento n.
Una buena solución es llevar la cuenta de los valores que ya han sido calculados, guardándolos en un diccionario. Un valor ya computado que es guardado para uso futuro se llama un memo. Aquí tenemos una implementación de fib que utiliza memos:
ya_conocidos = {0: 0, 1: 1}
def fib(n):
if n not in ya_conocidos:
nuevo_valor = fib(n-1) + fib(n-2)
ya_conocidos[n] = nuevo_valor
return ya_conocidos[n]El diccionario ya_conocidos lleva la cuenta de los números de Fibonacci que ya conocemos. Comenzamos con sólo dos pares: 0 mapea a 0 y 1 mapea a 1.
Cada vez que se llame a fib, ésta chequea el diccionario para determinar si contiene el resultado. Si está allí, la función puede retornar de inmediato sin necesidad de hacer más llamados recursivos. En caso contrario tendrá que computar el valor. El nuevo valor se agrega al diccionario antes de que la función retorne.
Utilizando esta versión de fib, nuestras máquinas pueden computar fib(100) en un abrir y cerrar de ojos.
>>> fib(100) 354224848179261915075
E incluso mucho más, también en un abrir y cerrar de ojos!
>>> fib(200) 280571172992510140037611932413038677189525 >>> fib(300) 222232244629420445529739893461909967206666939096499764990979600 >>> fib(400) 176023680645013966468226945392411250770384383304492191886725992896575345044216019675 >>> fib(500) 139423224561697880139724382870407283950070256587697307264108962948325571622863290691557658876222521294125 >>> fib(600) 110433070572952242346432246767718285942590237357555606380008891875277701705731473925618404421867819924194229142447517901959200 >>> fib(700) 87470814955752846203978413017571327342367240967697381074230432592527501911290377655628227150878427331693193369109193672330777527943718169105124275 >>> fib(800) 69283081864224717136290077681328518273399124385204820718966040597691435587278383112277161967532530675374170857404743017623467220361778016172106855838975759985190398725 >>> fib(900) 54877108839480000051413673948383714443800519309123592724494953427039811201064341234954387521525390615504949092187441218246679104731442473022013980160407007017175697317900483275246652938800 >>> fib(1000) 43466557686937456435688527675040625802564660517371780402481729089536555417949051890403879840079255169295922593080322634775209689623239873322471161642996440906533187938298969649928516003704476137795166849228875
- Y se puede seguir mucho más allá!
>>> fib(3500) 128013529779468136153585136825101961538900481122065445964837651183086898754026550517136497483483470641608626276464055059332628575928521597999901718592957423352363167465917636140408184822379391543598931815814725878528845711814356562816020703656120345663431005792446926782064141406206872674044496382612109555705276756054608939403080010257497520565825039141232590185236536300243432404427078483449695275223922784635210975743019657462141365577883788628334421325013343898945369582265133225052581547429120787483968895443714869214153983484196368957200111230649716136282989616442150717747827588840460128198812637224475960962985001698982034192388374058622072865322851268191822192497641904232912275607663029887240803055414422300714028137340125
20.6) Contando letras
En los ejercicios del capítulo 8 (Strings) escribimos una función que contaba el número de ocurrencias de una letra en un string. Una versión más general de este problema es formar una tabla de frecuencias de las letras en el string, cuántas veces aparece cada letra.
Tal tabla de frecuencia puede ser útil para comprimir un archivo. Dado que diferentes letras aparecen con diferentes frecuencias, podríamos comprimir un archivo utilizando códigos más cortos para letras comunes y códigos más largos para letras que aparecen esporádicamente.
Los diccionarios proveen de una forma elegante para generar una tabla de frecuencias:
cuenta_de_letras = {}
for letra in "Mississippi":
cuenta_de_letras[letra] = cuenta_de_letras.get(letra, 0) + 1print(cuenta_de_letras)
Produce el output:
{'M': 1, 's': 4, 'p': 2, 'i': 4}Comenzamos con un diccionario vacío. Para cada letra en el string, encontramos la cuenta actual (posiblemente cero) y la incrementamos. Al final, el diccionario contiene pares de letras y sus frecuencias.
Resulta una mejor presentación si mostramos la tabla de frecuencias en orden alfabético. Podemos hacer eso con los métodos items y sort, así:
>>> items_letras = list(cuenta_de_letras.items())
>>> items_letras.sort()
>>> print(items_letras)
[('M', 1), ('i', 4), ('p', 2), ('s', 4)]Observar que en la primera línea tuvimos que llamar al conversor de tipos list. Esto convierte la promesa que obtenemos con el método items en una lista real, un paso necesario antes de que podamos utilizar el método sort del tipo list.
20.7) Glosario
- grafo de llamadas, diccionario, valor de dato inmutable, valor de dato mutable, clave, par clave:valor, memo
- tipo de mapeo (mapping type)
- Se llama tipo de mapeo a un tipo de datos compuesto por una colección de claves y sus valores asociados. El único tipo de mapeo incorporado en Python es el diccionario. Los dicccionarios implementan el tipo de datos conocido como array asociativo en otros lenguajes de programación.
20.8) Ejercicios
1) Escribe un programa que lea un string y retorne una tabla con las letras del alfabeto en orden alfabético que ocurren en el string junto con la cantidad de veces en que cada letra ocurrre. Ignorar mayúsculas y minúsculas. Un ejemplo de output del programa se vería así, en este caso, cuando el usuario ingresa el texto: “ThiS is String with Upper and lower case Letters”: (hacerlo)
a 2 c 1 d 1 e 5 g 1 h 2 i 4 l 2 n 2 o 1 p 2 r 4 s 5 t 5 u 1 w 2
2) Dar la respuesta del intérprete de Python a cada uno de los siguientes, en una sesión continua con el intérprete:
- a.
- b.
- c.
- d.
- e.
- f.
- g.
>>> d = {"manzanas": 15, "bananas": 35, "uvas": 12}
>>> d["bananas"]>>> d["naranjas"] = 20 >>> len(d)
>>> "uvas" in d
>>> d["peras"] = 20
>>> d.get("peras", 0)>>> frutas = list(d.keys()) >>> frutas.sort() >>> print(frutas)
>>> del d["manzanas"] >>> "manzanas" in d
- Respuestas: (a) 35; (b) 4; (c) True; (d) KeyError: 'peras'; (e) 0; (f) ['bananas', 'manzanas', 'naranjas', 'uvas']; (g) False
- Asegúrate de comprender el por qué de cada resultado. Luego aplica lo que aprendiste para rellenar el body de la siguiente función:
def agregar_fruta(inventario, fruta, cantidad=0):
return
# Haz que funcionen estos tests...
nuevo_inventario = {}
agregar_fruta(nuevo_inventario, "frutillas", 10)
test("frutillas" in nuevo_inventario)
test(nuevo_inventario["frutillas"] == 10)
agregar_fruta(nuevo_inventario, "frutillas", 25)
test(nuevo_inventario["frutillas"] == 35)- Respuesta:
def agregar_fruta(inventario, fruta, cantidad=0):
if (inventario.get(fruta, 0) == 0):
inventario[fruta] = cantidad
else:
inventario[fruta] += cantidad;
3) Escribe un programa llamado palabras_de_alicia.py que cree un archivo de texto de nombre palabras_de_alicia.txt que contenga una lista alfabética de todas las palabras, y la cantidad de veces que cada una ocurre, en el texto que hemos usado en el capítulo 14: Alice in Wonderland (Alicia en el País de las Maravillas).
- Las primeras 10 líneas de tu archivo de salida deberían verse así:
Palabra Recuento ======================= a 631 a-piece 1 abide 1 able 1 about 94 above 3 absence 1 absurd 2
- ¿Cuántas veces aparece la palabra alice en el libro? (hacerlo)
4) Cuál es la palabra más larga en el libro Alice in Wonderland? Cuántas letras tiene? (hacerlo)